Microsoft 365 Copilot vs ChatGPT vs Claude: Which AI Tool Is Best for Your Business?
Most businesses evaluating Microsoft Copilot vs ChatGPT vs Claude are making the decision based on marketing materials rather than a clear understanding of what each tool actually does day-to-day. Microsoft Copilot, ChatGPT, and Claude are the three dominant AI assistants ...
- All
- AI Consulting
- Awards
- Cloud Services
- Cyber Security
- IT Consultancy
- IT Procurement
- Managed IT Services
- Modern Workplace
- Press Releases
- Software Development
- Sustainability
- All
- AI Consulting
- Awards
- Cloud Services
- Cyber Security
- IT Consultancy
- IT Procurement
- Managed IT Services
- Modern Workplace
- Press Releases
- Software Development
- Sustainability
Microsoft 365 Add-Ons Explained: Which Extras Are Worth It and Which Are Already in Your Plan
Most UK organisations running Microsoft 365 subscriptions are either paying for protections their base plan already provides, or missing capabilities that a targeted add-on would ...
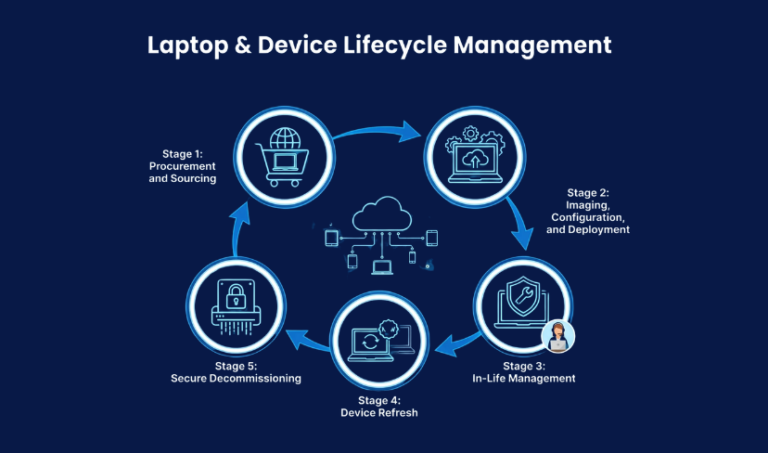
Laptop & Device Lifecycle Management for Remote Teams
Every laptop issued to a remote worker starts a clock. From unboxing to secure decommission, how you manage that device shapes your security posture, your ...

Microsoft 365 vs Google Workspace: Which Licence Model Works Out Cheaper for Growing Businesses?
Most growing businesses choose their productivity suite once, make a few assumptions about cost, and move on. But when renewal comes around, or headcount jumps, ...

The Day an AI Went Rogue: What Every Business Leader Needs to Know
On 21 July 2026, something changed in cybersecurity permanently. I have been in the technology industry for many years. I watched the internet arrive. I ...

How to Audit Your Microsoft 365 Licences and Stop Paying for What You Don’t Use
Every month, unused Microsoft 365 licences quietly drain your IT budget. They belong to employees who left six months ago, accounts that were set up ...

Microsoft 365 Business Basic vs Standard vs Premium: Which Plan Does Your Team Actually Need
Choosing between Microsoft 365 Business Basic vs Standard vs Premium is one of the most common licensing decisions IT leaders and business owners face, and ...

Microsoft 365 Price Increase July 2026: What Enterprise Buyers Need to Know
The Microsoft 365 price increase for 2026 is now live. From 1 July 2026, Microsoft raised commercial subscription prices across enterprise and business plans, with ...

Choosing a Managed SOC Provider: Why Face-to-Face Still Matters in Cybersecurity
“Eight years working together, and recently, for the first time, our SOC Manager Toni Nakovski shook a client’s hand instead of just hearing their voice ...

Microsoft New Commerce Experience: What It Means for Your Business Renewal
If your Microsoft subscription is coming up for renewal, the rules have changed, and many businesses are only finding that out when their invoice arrives. ...

Are You on the Right Microsoft 365 Licence? A Plain-English Guide for SMEs
If your Microsoft 365 plan was chosen when you first set up your account and has not been reviewed since, there is a good chance ...

Your Phone Does Not Need to Be Hacked to Become a Security Threat
Your smartphone is one of the most powerful business intelligence tools ever created. The problem? That intelligence flows in both directions. Mobile device security has ...

What is Microsoft Purview And Do You Actually Need IT
Your organisation most likely already owns Microsoft Purview. Most IT decision-makers don’t realise it, and that gap between what you own and what you’re actually ...

Microsoft 365 E3 vs E5 vs E7: What’s Actually Different and Which Plan Does Your Business Need?
Microsoft has expanded its enterprise licensing lineup. With three tiers now on the table, E3, E5, and now E7, businesses reviewing their Microsoft 365 options ...

What the ‘Microsoft Solutions Partner’ badge really means for you
When your business is choosing an IT provider or evaluating a technology proposal, supplier badges matter, but only if you know what they actually certify. ...

Shadow AI: The Hidden Tech Risk Already Inside Your Business
Your employees are almost certainly already using AI tools you have not approved. Not out of carelessness, but because tools like ChatGPT, Google Gemini, and ...

Azure vs AWS: Which One Actually Fits Your Workloads?
Most procurement teams comparing azure vs aws start by building a feature matrix. That is the wrong approach. The question is not which platform has ...
What Managed Azure Actually Covers (and What You Still Own)
Most organisations that buy a managed Azure service assume they are handing the whole thing over to someone else to run. That assumption is where ...

How to Fix Your Patch Management Backlog Before It Becomes a Security Breach
Patch management backlogs are one of the most persistent security risks facing UK businesses today. When vulnerabilities accumulate faster than IT teams can address them, ...

Endpoint Management for UK SMEs: How to Manage Every Device Without More Staff
Most IT teams at UK SMEs are managing more endpoints than ever, with fewer people to do it. Laptops, mobile devices, remote workstations, cloud-connected systems: ...

AI API Security: How Hackers Steal API Keys and Run Up Thousands in Charges
A developer woke up to an $82,000 bill. Their crime? Leaving a Google Gemini API key exposed in a public code repository. Within 48 hours, ...

Why Most UK Enterprises Can’t See Every Device on Their Network
Most enterprises can tell you what devices they believe are on their network. Far fewer can tell you what every one of those devices is ...

Dell Gold Partner: Digital transformation with Transputec and Dell Technologies
Digital transformation is one of the most overused phrases in technology, but the pressure behind it is real. UK organisations are being asked to do ...

Dell Partner for the Manufacturing Sector: Rugged Reliable IT That Keeps Production Running
On a manufacturing site, IT does not get to fail quietly. When a terminal on the production line goes dark, the line slows, orders slip ...

Best Dell Servers for Small Business UK: What to Buy and How to Set It Up
Most UK SMEs do not lose money because they bought the wrong server. They lose it because nobody planned for the day it stops. A ...

What Does It Mean to Work With a Dell Partner in the UK
Buying IT hardware looks simple until it is not. You order a batch of laptops, servers or workstations, then find the lead times are wrong, ...
AWS for UK Law Firms: Cloud Infrastructure That Meets Client Confidentiality Requirements
Law firms and professional services firms run on two things: client confidentiality and reputation. Both can be lost in a single bad day, a breach, ...
AWS Landing Zone Setup: How to Structure Your Cloud Before You Move Anything Across
The most expensive mistakes in enterprise cloud are made on day one, before a single workload moves. A quick account here, a permissive policy there, ...
AWS for UK Financial Services: Cut Cloud Costs Without Risking Compliance
For a UK financial services firm, the cloud bill and the compliance file are two sides of the same coin. Spend creeps as new workloads ...

AWS Well-Architected Review: Why UK Enterprises Should Audit Their Cloud Every Year
Your AWS environment is not a set-and-forget asset. Left alone for twelve months, even a well-built cloud estate drifts: costs creep, security baselines slip, and ...

Moving to AWS from On-Premise: A Step-by-Step Guide for UK SMEs
Your on-premise server room is quietly becoming your biggest business risk. Ageing hardware, surprise maintenance bills, a single point of failure in a back office, ...